Download a website recursively with wget In Linux Step By Step Tutorial
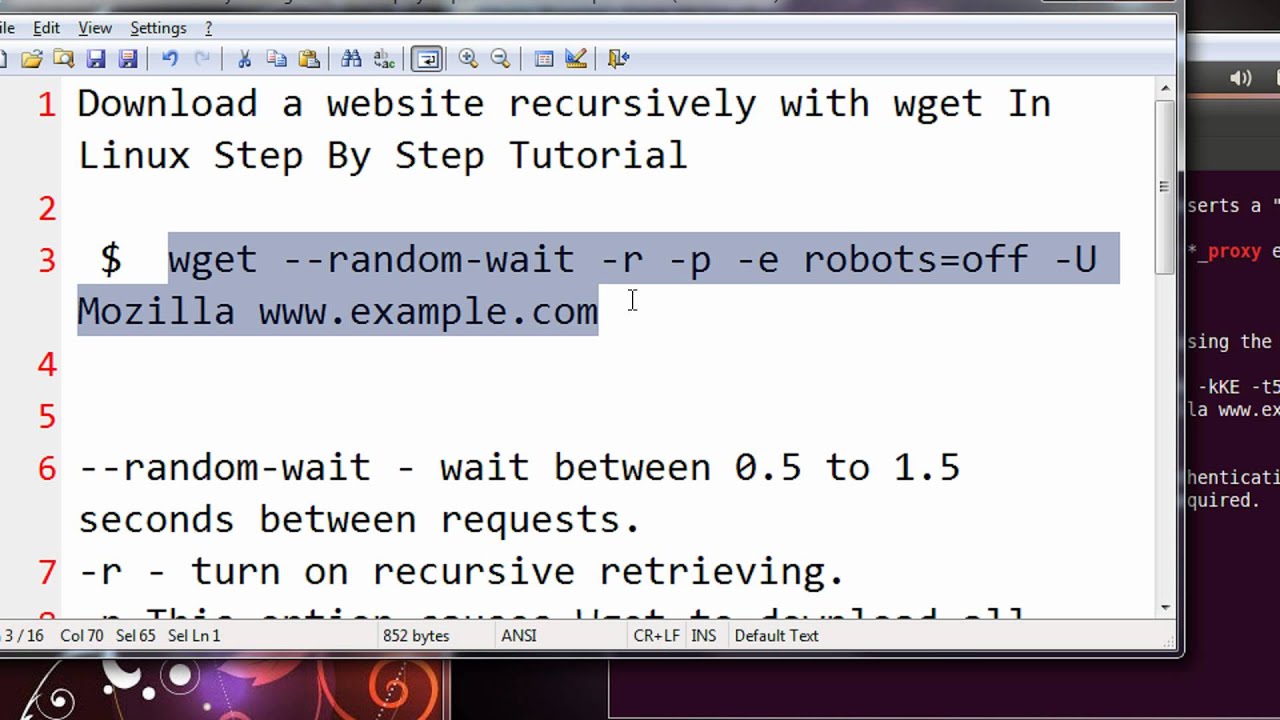
Download a website recursively with wget In Linux Step By Step Tutorial
$ wget –random-wait -r -p -e robots=off -U Mozilla www.example.com
–random-wait – wait between 0.5 to 1.5 seconds between requests.
-r – turn on recursive retrieving.
-p This option causes Wget to download all the files that are necessary to properly display a given HTML page
-e robots=off – ignore robots.txt.
-U Mozilla – set the “User-Agent” header to “Mozilla”. Though a better choice is a real User-Agent like “Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729)”.
Some other useful options are:
–limit-rate=20k – limits download speed to 20kbps.
-o logfile.txt – log the downloads.
-l 0 – remove recursion depth (which is 5 by default).
–wait=1h – be sneaky, download one file every hour.
by Mayank Agarwal
linux download


