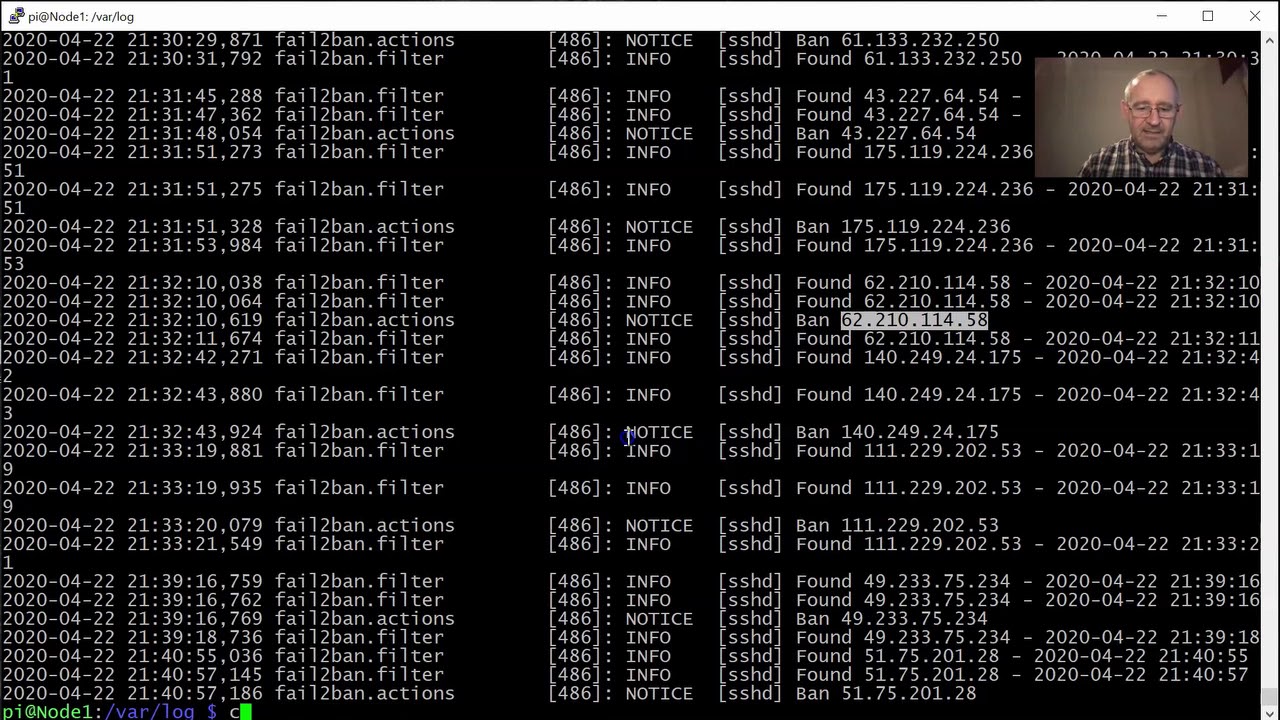
Filtering .log files, with cat, grep, cut, sort, and uniq
Using “cat”, “grep”, “cut”, “sort”, “uniq”, and “wc” ALL in one line, I show you how to filter information from a .log file, and you find out just how important strong passwords really are. This video was recorded during an online instructional session and is intended for educational purposes.
by Hackpens
linux web server



thanks for the amazing video
love it <3
Muy buen video, gracias por compartir, saludos desde México
nice , except cut -d " " -f x not working for me , i will dig durther to figure out why..
Thanks.. very helpful and will be using this as a reference from now on
6:36 someone tried Minecraft lol
you don't need cat, just use grep "string" auth.log also, you instead of cut, just use awk '{print $11}'
😊 great videos 👍 thank you!!!
Now dump all the unique IPs into a text file, and run nslookup on each one. $50 says they all are located in China or Russia. At least %98-99 of them. At least that's what I always end up finding.
Quick revision:
#cat auth.log | grep "invalid" | cut -d " " -f 11 | sort | uniq | wc -l
#cat fail2ban.log | grep "Ban" | grep -v "Restore" | cut -d " " -f 16 | sort | uniq -d > ~/uniq_ips.txt
Great introduction to the topic, a few things that i think are worth mentioning, once people have learned the commands that were being demonstrated:
If the logs your using have a variable amount of spaces between columns (to make things look nice), that can mess up using cut, to get around that you can use `sed 's/ */ /g` to replace any n spaces in a row with a single space. You can also use awk to replace the sed/cut combo, but that's a whole different topic.
uniq also has the extremely useful -c flag which will add a count of how many instances of each item there were.
And as an aside if people wanted to cut down on the number of commands used you can do things like `grep expression filepath` or `sort -u` (on a new enough system), but in the context of this video it is probably better that people learn about the existence of the stand alone utilities, which can be more versatile.
Once you're confident in using the tools mentioned in the video, but you still find that you need more granularity than the grep/grep -v combo, you can use globbing, which involves special characters that represent concepts like "the start of a line"(^) or the wildcard "any thing"(*) (for example `grep "^Hello*World"` means any line that starts with Hello, and at some point also contains World, with anything or nothing in-between/after). If that still isn't enough you might want to look into using regular expressions with grep, but they can be even harder to wrap your mind around if you've never used them before. (If you don't understand globbing or re really are just from reading this that's fine, I'm just trying to give you the right terms to Google, because once you know something's name it becomes infinitely easier to find resources on them)
I am checking this video 3year after upload. The video tutorial is on point and clear.
Thanks! That was informative. The only thing I would have done differently is flip the order of uniq -d and sort. Less items to sort after uniq filters them out.
from the ip addres can you find out their location ?
Concept explained well in a short video.
Simple and straightforward ❤
From description: > "I show you how to filter information from a .log file, and you find out just how important strong passwords really are."
i always wondered that pattern matching has smth to do with password security, but then i thought, you have to have passwords to apply pattern matching on 'em right? 'cz the password input field of a site doesn't accept regex, and generating exhaustive strings from regex doesn't help either…
so, what are scenario we are imagining for talking about regex in context of secure passwords?
Good
Gold sir 🔥
Hi Sir, I have a log file which I cannot see after the command cd /var/log Please give me some suggestions thank you
Great info and an enjoyable watch 👍👏
Awesome tutorial on cat and grep, Thanks…
You sir are incredible at teaching
16 th field from experience still blow away
thank you this is very helpful
thank you so much for this tutorial it helped me a lot with understanding of cat, grep and sort.
Are you able to tell me what this command would do "cat -rf ~/syslog | sort | grep -iaE -A 5 'cpu[1-7].*(7[0-9]|8[0-9]|100)' | tee cpu.txt" specifically the numbers after cpu which seem to me like it's a time stamp
One word.……….…………$Π¶€®
Awesome video! Please don’t stop making Linux, bash, ethical hacking related videos. Thank you. Subscribed!! 😊
I was searching for all command combinations in reading logs to extract an info. this video is great.
Hi,
great videos again 😀
Is this amaount of tried logins normal ? If so, this is a bit scary…
Is there a way to "hide" the server ? Im a beginner, pls excuse a potential dumb questions/statement.
Back in late 90's I wrote a script to track backup take useage.
Thanks a lot that's very helpfull
I would like to see more cases of analyzing the logs, to learn from you build more experience in that regard thanks
I put a custom messge saying it's the FBI'S system that displays on every ssh attempt
awk '{print $11}'
Honestly i was looking for a long time for some good videos for linux, and sir I can tell you, your videos are gold! Thx a lot!
This video has been hugely helpful to me when parsing through log files of numerous types manually (IPtables, Netflow, SSH). Thank you very much mate.
Cool
You want the duplicates if they are from different source IP addresses as this means that different people have tried the same user names to access your system
your awesome thank you Sir
that was one of the most useful and simple tutorial i've ever seen
You are very good at Linux, hope you continue sharing your knowledge!
@Hackpens very informative video mate. Thanks for sharing. What is this tool you are using? Do you have any video for beginner? I really need to learn this stuff. Kindly help.
Thanks again.
Very useful tutorial for me